Let’s take a look at how a message is handled by the Mailbox Server in terms of storage groups, databases, and transaction logs.
When
you install Exchange, by default, a First Storage Group is created with
a single database. You can add more storage groups (up to 5 for the
Standard Edition or up to 50 for the Enterprise Edition) and within
each one of those storage groups, you can add databases (up to 5 for
the Standard Edition or up to 50 for the Enterprise Edition). Each
database you add has the *.edb extension. If you create a mailbox and
place it within a database within a storage group, when that mailbox
receives mail, the Exchange Server adds it to the database.
Understandably, these databases grow as more mail is added.
When
an email message enters the Mailbox server, it goes through the memory
and is written to transaction logs. Each log is 1MB in size (a
reduction from 5MB in previous versions of Exchange). Depending on the
amount of traffic coming into the Exchange Server, the data is also
written to the database. Now the email message has been written to two
locations: the database where the user will check in using his email
client and retrieve his mail, and the transaction logs where the email
is broken up, depending on its size, into 1MB chunks.
Transaction
logs are created in a log stream; in other words, they follow a
sequential manner. Although the current log written to might look like
an E00.log, additional logs might look more like E000000002E (as you
can see in Figure 1).
There can be up to 2,147,483,647 log files in a log stream. The current
log is not committed to the database and does not have its name changed
until after it is filled to the full 1MB capacity. Then, it is closed
out.
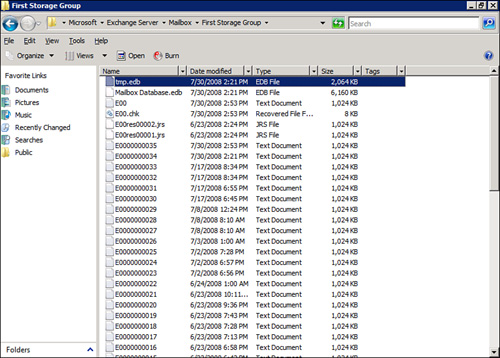
There
is a check file to keep track of which transaction logs have been added
to the database so that none are missed. A couple of reserve logs also
exist, just in case the disk space runs out and you need a little extra
space (although 2MB of extra transaction log space won’t buy you much).
Note
Each
storage group can handle multiple databases; however, it is recommended
that you place one database in one storage group. One key element to
keep in mind is that the transaction logs are intertwined with a
storage group. In the event you have three databases in the same
storage group, the transaction logs will continue to use the log stream
approach for all three at once. This might have a negative impact on
performance and disaster recovery at some point, which is why the
recommendation to use one database for each storage group exists.
The
goal with transaction logs is to provide redundancy for your database.
This can be a protection for you, but only if you separate the
transaction logs from your database.
Consider
the following scenario: You perform nightly backups of your Exchange
database. It’s Thursday, around 4:00 p.m., and the disk handling your
database crashes (or your database corrupts) and you need to restore
the database from backup. No problem, you have last night’s backup
handy. However, what about the mail from that day? It’s not going to be
in the backup of the database, right? However, it will be located in
those transaction logs. So, you restore the database, and the
transaction logs replay themselves into the newly restored database.
Obviously, this works only if the transaction logs are not ruined along
with the database. The obvious point is to separate the two onto
different disks.
Overall,
the best practice is to move your database and transaction logs off the
drive that holds the system files and then separate the database from
the transaction logs. To go one step further, if you can place your
databases on a form of striped volume (if redundancy is provided some
other way) or a striped volume with parity (a RAID 5 setup) to enable
fault tolerance, and if you can mirror your transaction logs, you can
achieve the best-practice level of storage for your mailbox servers.